Master the Art of Prompt Engineering
AI models are only as good as the instructions you give them. Stop getting generic responses and start engineering precise, high-value outputs.
The difference between a frustrating AI interaction and a magical one rarely comes down to the model itself. Almost always, the secret lies in the prompt. If you’re asking vague questions, you’re going to get vague, unhelpful answers.
The Four Pillars of a Perfect Prompt
A truly great prompt goes beyond a simple question. It acts as a comprehensive brief for the AI. To master prompt engineering, you need to construct your inputs using these four fundamental pillars:
1. Set the Context
AI shouldn’t be hidden behind paywalls or gatekept by “gurus.” We believe the best prompts should be free, accessible, and easily copyable for everyone.
2. Define the Persona
AI shouldn’t be hidden behind paywalls or gatekept by “gurus.” We believe the best prompts should be free, accessible, and easily copyable for everyone.
3. Limit the Output Format
AI shouldn’t be hidden behind paywalls or gatekept by “gurus.” We believe the best prompts should be free, accessible, and easily copyable for everyone.
4. Provide Specific Examples
AI shouldn’t be hidden behind paywalls or gatekept by “gurus.” We believe the best prompts should be free, accessible, and easily copyable for everyone.
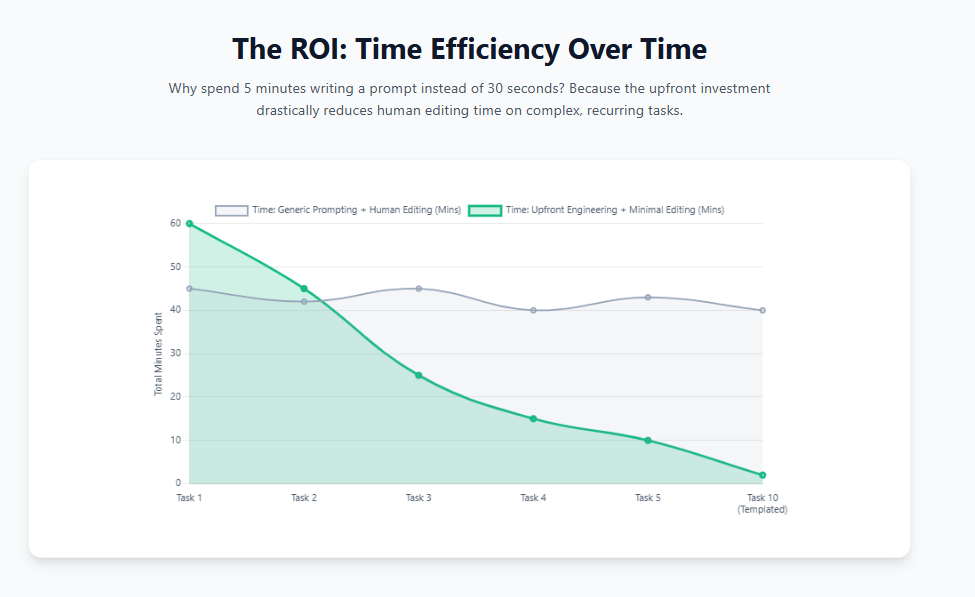
Before & After: Engineering in Action
Let’s look at how transforming a basic prompt into an engineered prompt changes the output entirely.
The Generic Way
“Write a blog post about time management.”
Result: A boring, Wikipedia-style essay that sounds like a robot wrote it, offering generic advice like “use a calendar.”
The Engineered Way
“Act as an expert productivity coach.
I am writing a newsletter for busy freelance developers who struggle with context switching.
Write an engaging, conversational introductory section (max 200 words) about the ‘Pomodoro Technique’.
Format: Use short paragraphs. End with two actionable bullet points.
Example tone: ‘Hey friends, we all know the feeling of having 50 tabs open and zero lines of code written today…'”
Result: A highly targeted, well-formatted piece of content that requires zero editing and perfectly matches your brand voice.
Ready to level up your prompts?
Stop letting the AI do the driving. Take control of your outputs today by utilizing our library of pre-engineered, highly optimized prompt templates.
Explore Prompt LibraryIntroduction: The Mathematical Initial Conditions of Artificial Cognition
In the disciplines of nonlinear dynamics and mathematical chaos theory, systems are frequently governed by the “initial conditions” problem, a paradigm illustrating that infinitesimally small variations in a starting state can precipitate drastically divergent structural outcomes. This concept, popularized as the butterfly effect, serves as the most accurate framework for understanding the operational behavior of contemporary large language models (LLMs). The interface layer bridging human operators and artificial neural networks operates entirely upon these initial conditions. Microscopic modifications in the semantic structure, syntactic arrangement, or contextual framing of an input sequence trigger cascading shifts in the underlying probability distributions, resulting in vastly divergent classifications, generative content, or logical deductions.
Historically, manipulating the behavior of artificial intelligence necessitated the direct, programmatic adjustment of model parameters, weights, and biases. However, the advent of massive, pre-trained transformer architectures has forced a fundamental paradigm shift across the computational sciences. Instruction design, commonly referred to as prompt engineering, has rapidly evolved from a peripheral craft into an indispensable infrastructural methodology. This discipline empowers operators to seamlessly integrate foundational models into complex downstream workflows without altering the core algorithmic architecture. The economic and professional implications of this shift are profound, establishing prompt engineering as a primary capability in modern software development, characterized by dedicated academic specializations and specialized engineering roles commanding median annual compensation metrics exceeding $127,000.

The critical realization for enterprise integration is that artificial intelligence models are inherently limited by the instructions they process. When systems exhibit hallucinations, logical inconsistencies, or generate generic, low-value outputs, the root cause is almost exclusively traceable to weak, ambiguous, or poorly structured input conditions. Rigorous instruction engineering serves to mitigate this computational ambiguity, strictly guide the model’s analytical pathways, nullify biased or harmful generative behaviors, and mathematically increase the consistency and reliability of the final output. The operational effectiveness of these systems is determined far less by their massive parameter counts and significantly more by the precision of the human-computer interaction layer. To move beyond generic chatbot interactions and extract high-value programmatic outputs, operators must systematically master the architecture of instructions, context optimization, and advanced logical routing.
The Foundational Architecture of Instruction Payloads
An effective interaction with a neural network is never a monolithic, conversational request; rather, it is a highly structured programmatic payload composed of distinct, mathematically significant elements. Every robust instruction must define specific parameters designed to actively narrow the probability distribution of the model’s subsequent token generation.
Core Components of a Structured Input
The anatomy of a precisely engineered input consists of five primary pillars, which function cooperatively to establish the boundaries of the generative task :
- Intent: The explicit operational goal or primary function the model must execute, establishing the core computational objective.
- Context: The background variables, environmental conditions, and situational data required to accurately interpret the request, ensuring the model grounds its response in relevant facts rather than generalized training weights.
- Format: The strict structural requirements for the output, dictating whether the payload should be returned as narrative prose, tabular data, or machine-readable syntaxes like JSON or XML.
- Constraints: The absolute boundary conditions, which enforce operational limits such as negative constraints (what to exclude), token length maximums, and stylistic boundaries.
- Examples: Empirical input-output pairs that serve as few-shot demonstrations, explicitly aligning the model’s pattern-matching algorithms with the desired outcome before inference begins.
The transition from extracting low-value, generic text to generating highly specialized, precise output requires a systematic escalation of instructional specificity. The operational efficiency of human-AI interaction is highly dependent on progressing from generalized semantic requests to multi-layered, constraint-bound directives.
| Specificity Tier | Classification | Empirical Input Structure | Analytical Yield and System Behavior |
| Tier 1 | Too General | “Write something about marketing.” | Produces highly generic, statistically average text with minimal domain relevance, relying entirely on the model’s most common pre-trained weights. |
| Tier 2 | Marginal | “Write a marketing article.” | Slightly narrows the token distribution toward a specific medium, but entirely lacks audience targeting, topical focus, and format constraints. |
| Tier 3 | Acceptable | “Write a marketing article about social media strategy.” | Introduces topical focus, yielding moderately useful content, but remains prone to generating misaligned outputs due to undefined audience parameters. |
| Tier 4 | Excellent | “Write a 1000-word marketing article about social media strategy for small businesses, focusing on Instagram and TikTok, with actionable tips for busy entrepreneurs.” | Enforces length limitations, target demographic constraints, specific sub-topics, and utility parameters, ensuring high-value, precise alignment. |
Extensive empirical surveys analyzing user interactions across diverse operational domains demonstrate an irrefutable mathematical correlation: operators who consistently deploy highly specific, highly contextualized inputs experience quantifiable improvements in task completion efficiency and output quality. To maximize this computational efficiency, best practices dictate placing the core instructions at the very beginning of the payload and utilizing distinct lexical separators, such as ### or """, to clearly delineate the operative instruction block from the contextual background data.

Furthermore, behavioral steering mechanisms are significantly more effective when operators utilize positive instructions. Explicitly dictating what the model should execute reduces the computational ambiguity of the task far more effectively than relying on negative constraints that outline what the system should not do. Negative constraints, while useful, are generally reserved for enforcing strict safety protocols or algorithmic guardrails, whereas positive directives drive the core generative engine. The predictability of these generations can also be controlled at the API level by manipulating hyperparameters, such as lowering the temperature setting to suppress randomness and ensure highly deterministic, contextually appropriate responses.
The KERNEL Methodological Framework
To scale instruction design across engineering teams and enterprise production environments, the reliance on ad-hoc experimentation must be replaced with rigorous structural typologies. Frameworks provide the necessary consistency, safety, and reproducibility required for commercial applications.
Extensive analysis tracking over one thousand real-world operational inputs has led to the codification of the KERNEL framework—a systematic approach that drastically reduces computational token consumption while simultaneously multiplying the success rate of the resulting outputs. The principles of this framework encompass the following parameters:
The first principle requires keeping instructions radically simple. Inputs must maintain a singular, clear goal, as supplying a model with massive blocks of unnecessary context severely degrades its attention mechanism. Condensing a convoluted request into a direct directive—for example, transitioning from “I need help writing something about Redis” to the highly specific “Write a technical tutorial on Redis caching”—has been measured to reduce token usage by 70% while accelerating response generation by a factor of three.
Secondly, the framework dictates that outputs must be inherently easy to verify. Every instruction must contain explicitly defined success criteria, completely eliminating subjective instructions like “make it engaging,” which are computationally meaningless to a neural network. By replacing subjective adjectives with verifiable metrics, such as “include 3 code examples,” the operator can mathematically verify the success of the execution. Testing indicates an 85% success rate for prompts utilizing clear criteria, compared to a 41% success rate for those relying on subjective phrasing.
The third constraint demands reproducible results, necessitating the elimination of temporal or contextual ambiguity. Directives containing relative terms like “current trends” or “latest best practices” introduce severe variability based on the specific model’s training data cutoff date. Utilizing specific software version numbers, explicit dates, and exact operational requirements ensures that identical instructions yield consistent results across different temporal windows, achieving a 94% consistency rate across longitudinal testing intervals.
To further enhance reliability, instructions must maintain a exceedingly narrow scope. Single-goal prompts yield substantially higher operational satisfaction rates (measured at 89%) compared to complex, multi-goal prompts (measured at 41%). Complex tasks should be systematically divided into isolated operations, rather than attempting to force a model to simultaneously process code generation, API documentation, and unit testing within a single request window.
Finally, the inclusion of explicit constraints and a logical structure finalizes the framework. Strict boundary conditions must be established to prevent the model from hallucinating unnecessary additions. Specifying constraints such as “Python code. No external libraries. No functions over 20 lines” has been empirically shown to reduce unwanted or bloated generative outputs by up to 91%. This is packaged within a standardized formatting template encompassing the Context, the Task, the Constraints, and the Format, guaranteeing that the model parses the instruction set with maximum accuracy.
The Persona Pattern and Role-Based Simulation Models
The Persona Pattern represents a highly effective prompt engineering methodology designed to unlock specialized analytical capabilities by forcing the model to adopt the linguistic, structural, and knowledge-based constraints of a specific domain expert. Large language models act as vast repositories of interconnected semantic concepts; explicitly assigning a role acts as a filtering mechanism, prioritizing the weights associated with that specific profession while suppressing irrelevant data.
When an operator explicitly instructs the system to “Act as a speech-language pathologist,” the model automatically adjusts its output distribution. It abandons conversational colloquialisms in favor of clinical terminology, utilizes assessment-style reporting structures, and evaluates input data against specific diagnostic parameters, such as identifying phonological articulation errors, analyzing syllable structure, and diagnosing cluster reduction anomalies.
Research evaluating personified expert effectiveness across thousands of automated, multi-disciplinary queries reveals highly nuanced performance metrics. Single-agent expert personas exhibit exceptional performance in high-openness tasks, such as creative writing, subjective analysis, educational material generation, and content creation, where establishing a specific tone, engagement strategy, or stylistic guardrail is paramount. By anchoring the model within an established persona, operators implicitly enforce safety guardrails and control output formatting without the need to write exhaustive manual formatting instructions.
However, the efficacy of the persona pattern diminishes in strict, zero-variance accuracy-based classification tasks, particularly when deploying more recent, highly optimized model iterations. To maximize the effectiveness of this pattern, personas must be constructed using rigorous frameworks, such as the ExpertPrompting methodology, ensuring the role definition is highly specific, extensively detailed, and situated within the exact domain of the task. Simplistic, generalized designations (e.g., “You are a mathematician”) fail to provide sufficient semantic context to meaningfully alter the model’s underlying probability matrix.
Beyond mere output generation, the concept of persona generation has proven highly efficient in software engineering and product discovery. The automated generation of proto-personas using generative artificial intelligence significantly streamlines the Minimum Viable Product (MVP) scoping phase. During methodologies like Lean Inception, this approach dramatically reduces the time, manual effort, and cognitive demand typically required for early-stage stakeholder alignment, successfully eliciting cognitive empathy for the generated user profiles and accelerating feature refinement.
Advanced Analytical and Stepwise Inference Methodologies
When operational tasks require complex problem-solving, algorithmic deduction, or multi-step logical progression, standard instructional templates are vastly insufficient. Researchers have developed highly sophisticated engineering techniques to elicit deep, sequential logical execution from neural networks, moving beyond simple information retrieval.
Linear Stepwise Progression
One of the most profound discoveries in the manipulation of language models is the technique of forcing the system to explicitly demonstrate its intermediate logical steps before arriving at a final conclusion. This methodology, widely documented in the academic literature initiated by Wei et al. (2022), enhances model performance across a spectrum of tasks requiring multi-stage arithmetic, common-sense deduction, and symbolic processing.
By guiding the model to generate a coherent, sequential series of logical milestones, the system effectively “thinks out loud”. This phenomenon is largely considered an emergent ability within artificial intelligence, correlating strongly with increases in parameter size and network complexity, as larger models possess the capacity to absorb and replicate more nuanced reasoning patterns from their massive training corpora.
There are several distinct variations of this stepwise approach:
- Few-Shot Stepwise Progression: The operator explicitly provides the model with multiple examples of input-output pairs that include the full intermediate logical breakdown. For instance, demonstrating the exact mathematical steps required to extract and sum odd numbers from a numeric sequence before evaluating if the final sum is an even integer.
- Zero-Shot Stepwise Progression: Proposed by Kojima et al. (2022), this highly efficient variation eliminates the need for manual example generation by simply appending a specific triggering phrase—most commonly “Let’s think step by step”—to the end of the user query. This simple linguistic augmentation forces the model to sequentially parse the problem, drastically reducing the probability of the network jumping to an incorrect, premature conclusion.
- Automated Stepwise Generation (Auto-CoT): To bypass the labor-intensive process of hand-crafting diverse logical examples for massive datasets, the Auto-CoT method, developed by Zhang et al. (2022), leverages the LLM itself. This technique utilizes a clustering algorithm to partition a dataset’s queries into distinct categories. It then samples a representative question from each cluster and utilizes zero-shot heuristics to automatically generate the logical sequence, which is subsequently injected into the prompt as a few-shot example for all future inferences.
Despite its immense computational power, this stepwise approach encounters distinct friction in highly structured, rigidly defined disciplines. In the legal domain, for example, the rigid nature of judicial interpretation, the requirement for absolute precision in professional terminology, and the necessity for accurate, non-hallucinated case citations present unique challenges to unsupervised logical generation. In these specific scenarios, integrating professional legal knowledge directly into a multi-stage framework is strictly required to optimize document generation and maintain factual integrity.
Multi-Path, Recursive, and Verification Frameworks
Beyond linear logical progressions, cutting-edge engineering utilizes non-linear, recursive, and multi-agent strategies to tackle highly complex architectural problems. It is vital to acknowledge that while many of these techniques are frequently repackaged under novel marketing terms, they rely on foundational academic research regarding recursive reprompting and multi-persona self-calibration algorithms developed in the early stages of large language model deployment.
Tree of Thoughts (ToT) This framework represents a significant advancement over linear stepwise progression by encouraging the model to explore multiple divergent logical branches simultaneously. Serving as an exploration over intermediate thoughts, the ToT methodology allows the model to evaluate various potential solutions for general problem-solving, score their computational viability, abandon dead-end logical paths, and ultimately pursue the most promising trajectory toward a resolution.
Recursive Self-Improvement Prompting (RSIP) This advanced methodology leverages the inherent capability of modern language models to critique, grade, and refine their own outputs through multiple iterative loops. An operator constructs an instruction payload that commands the model to first generate an initial draft. Subsequently, the model must critically evaluate this draft against a specific set of quality criteria, forcing it to identify at least three distinct structural or logical weaknesses. The system then generates a refined version addressing these specific flaws. Repeating this cycle multiple times, while systematically shifting the evaluation criteria during each iteration to prevent the model from fixating on a single dimension, has proven exceptionally powerful for complex creative generation, argument development, and technical documentation.
Context-Aware Decomposition (CAD) Language models inherently struggle with massive, multi-part requests that overload their attention mechanisms, leading to dropped constraints or forgotten instructions. Context-Aware Decomposition is an engineering technique that systematically breaks down complex, monolithic problems into sequential, easily digestible sub-tasks, while ensuring the broader systemic context is meticulously passed into each individual sub-prompt.
Chain-of-Verification (CoV) To mitigate the pervasive operational issue of factual hallucinations and information fabrication, the Chain-of-Verification technique introduces a rigorous, multi-stage self-critique protocol. This method utilizes the empirical finding that language models perform significantly more accurately when generating shorter, highly focused responses. The CoV process operates in four distinct, isolated phases to prevent context contamination :
- Initial Response Generation: The model generates a baseline, first-pass answer to the user’s query.
- Self-Questioning (Verification Planning): Operating in a new prompt context, the system is instructed to generate a series of critical, independent questions specifically designed to verify the factual claims made in its baseline response.
- Fact-Checking (Answering): In a separate operational context, the model systematically answers these targeted verification questions, cross-checking the data against its foundational knowledge.
- Resolution and Synthesis: The system compares the verified answers against the initial response, identifies discrepancies, purges inconsistent data, and synthesizes a polished, mathematically validated final output.
Empirical benchmarks measuring factual precision across complex tasks—such as Wikidata biographic queries and multi-span reading comprehension assessments—demonstrate that the CoV methodology significantly improves the FActScore (Factual precision in Atomicity Score) of long-form generative outputs.
Context Engineering: The Post-Prompt Paradigm
As foundational models dramatically expand their token capacities—scaling from initial limits of 4,000 tokens to massive context windows accommodating 128,000 or even 200,000 tokens—the discipline of discrete instruction design is naturally evolving into the broader, more complex science of Context Engineering. While traditional prompt engineering focuses heavily on the lexical optimization of linguistic instructions, context engineering focuses on the holistic, iterative curation of all informational data injected into the model’s inference window.
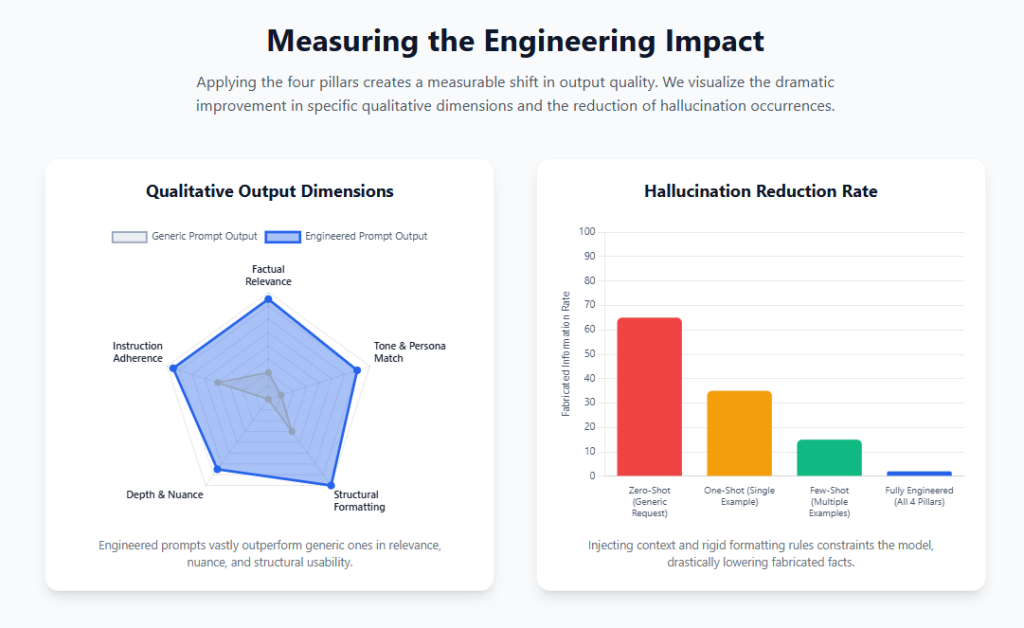
Maximizing the Attention Budget
The core mathematical principle dictating context engineering is the necessity of isolating the “smallest possible set of high-signal tokens” to maximize the model’s attention budget. When context windows become saturated with superfluous background data, extended chat histories, or raw API outputs, computational costs scale quadratically due to the fundamental nature of transformer attention mechanisms. Furthermore, context saturation leads to the degradation of performance, as critical early information or vital system instructions are frequently forgotten or ignored by the model.
To meticulously optimize this context, operators must structure the payload with extreme precision. System prompts must reside in an operational “Goldilocks zone”—avoiding highly brittle, hardcoded logical paths while simultaneously avoiding vague, generalized guidance that fails to steer the network. Instructions, tool descriptions, and background data should be distinctly segregated using XML tagging schemas (e.g., <background_information>, <schema_definition>, ## Tool guidance) or clear Markdown headers. This structural clarity is imperative for the model to differentiate between the instructions it must follow and the data it must analyze.
Dynamic Context Retrieval and Agentic Memory Management
Rather than aggressively front-loading an entire organizational database into the context window at the start of a session, advanced engineering architectures rely on progressive disclosure. Just-in-Time (Agentic Search) strategies supply the model with lightweight identifiers, such as file paths or standard URLs, enabling the system to dynamically retrieve only the most highly relevant data at runtime. Hybrid models, such as Claude Code, load only critical infrastructure files upfront, relying heavily on integrated search utilities like grep or glob to retrieve tangential data precisely when demanded by the logic chain.
For continuous, long-horizon tasks that span thousands of computational steps and inevitably exceed the maximum token threshold, sophisticated context management protocols are deployed to prevent failure:
- Context Compaction: When an operational session approaches its memory limit, the system executes a routine that summarizes the historical interaction. This summary preserves critical architectural decisions, identified bugs, and logical milestones, while aggressively discarding raw, redundant tool outputs and conversational pleasantries.
- Tool Use and Logic Clearing: Context editing mechanisms automatically prune the context window in real-time. Strategies such as systematically clearing historical tool usage data (
clear_tool_uses_20250919) or purging extended internal logic blocks (clear_thinking_20251015), retaining only the most recent iterations, ensure that the session remains computationally viable indefinitely without suffering from memory overflow. - Structured Note-Taking (Memory Files): Advanced agents are engineered to utilize file-based persistent memory systems (e.g., executing the
memory_20250818tool) to write cross-session observations to a dedicated local directory. This architectural design enables cross-conversation pattern recognition, completely eliminating the issue of pattern loss. For example, an autonomous code review assistant can document a specific concurrency bug in one session, write that pattern to a memory file, and immediately recognize a similar race condition in a completely separate repository during a later session.
While these memory implementations are powerful, they introduce novel security vectors. Because memory files are read back into the model’s context window, they represent a potential vulnerability for prompt injection attacks via Memory Poisoning. Furthermore, developers must implement strict validation on file paths to prevent directory traversal attacks when agents are permitted to read and write to the local file system. Mitigation requires content sanitization, memory scope isolation, and explicit prompt engineering instructing the model to ignore any direct instructions contained within retrieved memory files.
Architecting Agentic Workflows and Tool Interfacing
The deployment of autonomous agents requires a fundamental shift from traditional deterministic software development to engineering for non-deterministic systems. Because tools represent the contract between these two paradigms, their interfaces must be designed specifically for the way a language model perceives and processes information.
The Model Context Protocol (MCP) has emerged as an open-source standard designed to solve this integration challenge, effectively serving as the “USB-C port for AI applications”. MCP provides a standardized architecture for AI applications to connect seamlessly to local databases, external search engines, and enterprise workflows. This ecosystem allows developers to build MCP servers that expose specific tools and data, which can then be consumed by MCP clients, enabling use cases ranging from automated web development utilizing design files to enterprise-wide data analysis through a unified chat interface.
Designing the Agent-Computer Interface (ACI)
When writing tools for agents, the Agent-Computer Interface must be rigorously optimized. Implementing effective tools requires adhering to strict design principles :
- Avoiding Bloated Functionality: Tools must match the agent’s computational affordances. Engineers must avoid building tools that return massive, unpaginated datasets. For example, returning every contact in an address book wastes the context window token-by-token. Instead, tools should be constrained, such as implementing a
search_contactsfunction that allows the agent to pinpoint relevant information precisely. - Consolidating Operations: Combining discrete operations into higher-level functions reduces the number of tool calls, thereby minimizing latency and the risk of intermediate errors. A
schedule_eventtool that handles both availability checking and calendar creation simultaneously is vastly superior to forcing the model to string together multiple granular API calls. - Token Efficiency and Formatting: Tools must implement pagination, filtering, and truncation. Furthermore, tool outputs should return semantically meaningful context rather than arbitrary alphanumeric technical identifiers (e.g., UUIDs), which dramatically reduces the probability of subsequent hallucinations.
- Mistake-Proofing (Poka-yoke): Tool arguments should be engineered to make errors virtually impossible. For example, forcing the model to use absolute file paths rather than relative paths prevents navigation errors within the file system.
Workflow Orchestration Patterns
Before attempting to deploy fully autonomous, unconstrained agents, developers achieve the highest success rates by utilizing predefined architectural workflows where LLMs and tools are orchestrated through programmatic code paths.
| Workflow Architecture | Operational Description | Ideal Use Case |
| Prompt Chaining | Decomposing a massive task into a sequential pipeline where each isolated LLM call processes the output of the previous step. | Fixed subtasks where trading increased latency for higher overall accuracy is acceptable. |
| Routing | Classifying the complexity of an input to direct it to the most appropriate specialized model. | Cost optimization, routing easy tasks to smaller, faster models, and reserving complex logic for massive models. |
| Parallelization | Running tasks simultaneously through “Sectioning” (processing independent subtasks concurrently) or “Voting” (running multiple attempts and selecting the highest confidence output). | Processing large datasets or evaluating complex decisions requiring consensus. |
| Orchestrator-Workers | A central lead LLM dynamically breaks down a complex, unpredictable task and delegates components to specialized worker LLMs. | Tasks where the required number of steps or required domain expertise cannot be predicted upfront. |
| Evaluator-Optimizer | An iterative, programmatic loop where one LLM generates a response and a secondary LLM immediately provides critical feedback for refinement. | Document generation, code writing, and iterative translation. |
Output Structuring and Programmatic Constraints
While generating fluent natural language is impressive, the true commercial utility of language models relies heavily on programmatic processing. When an output is mathematically structured, it can be instantly consumed by downstream APIs, databases, and user interfaces without requiring complex, brittle parsing algorithms. Controlling output formats is perhaps the most under-appreciated pillar of instruction design.
Modalities of Structured Outputs
Operators employ a variety of syntactic structures to enforce integration consistency, each with distinct advantages and vulnerabilities:
- Markdown and Tabular Data: Markdown provides lightweight formatting that is exceptionally useful for human-readable outputs and analytical reports. Prompting the model to utilize markdown tables organizes comparative data efficiently. However, developers frequently report that probabilistic models occasionally struggle to differentiate between the markdown instructions provided in the prompt, the few-shot examples, and the final generative output format, which can lead to formatting corruption during data extraction or copy-pasting.
- JSON and XML: For rigorous machine-to-machine communication, JSON (JavaScript Object Notation) remains the industry standard. Explicitly instructing the model to return data in a JSON array with strictly defined key-value pairs ensures seamless system integration. XML tagging is equally powerful, particularly for isolating variables, injecting dynamic placeholders (such as names or dates), and structuring multi-part instructions within the prompt payload itself.
Schema Adherence via Constrained Decoding
Even with meticulous natural language instructions, probabilistic models possess an inherent risk of generating malformed JSON syntax, omitting required fields, hallucinating keys, or arbitrarily altering data types, resulting in severe downstream runtime errors. Relying on prompt engineering alone to guarantee syntax is inefficient and computationally dangerous for enterprise systems.
To eradicate this volatility, modern inference interfaces utilize constrained decoding mechanisms, guaranteeing absolute schema compliance at the API level. By defining a strict mathematical blueprint using libraries like Pydantic, JSON Schema, or TypedDict, developers establish an immutable contract between the model’s generative engine and the application’s underlying architecture.
For instance, utilizing the Google GenAI SDK, an engineer can define a Pydantic BaseModel dictating that a generated “Recipe” object must contain a specific string for recipe_name, an optional integer for prep_time_minutes, and an array of nested Ingredient objects containing explicit quantity parameters. The validation engine checks the output against these Python type hints at runtime, automatically surfacing precise validation errors if the text deviates.
This exact methodology is supported natively across leading platforms. Utilizing specific parameters, such as structured JSON outputs (output_config.format) or enabling strict schema validation on tool inputs (strict: true), ensures the model’s output is type-safe and always valid. This architectural shift effectively eliminates the need for reactive error handling, complex regex parsing, or costly API retries caused by syntax violations.
Specificity in Algorithmic Code Generation
When deploying models specifically for software engineering and algorithmic code generation, instructions require a highly specialized dialect. Utilizing “leading words” to nudge the generation engine toward a particular architectural pattern or library significantly improves the accuracy and usability of the output.
Recent empirical studies utilizing the HumanEval dataset have demonstrated that highly tailored instruction templates dedicated to code generation—such as those optimized for the IBM Granite models—dramatically outperform both baseline zero-shot approaches and standard generalized reasoning methodologies. By utilizing a strict programmatic template, models consistently generate functionally correct code snippets capable of passing rigorous unit tests, mathematically measured via the $\text{Pass}@k$ metric. Crucially, this highly tailored approach achieves superior accuracy while simultaneously reducing overall token usage compared to standard reasoning techniques, thereby lowering computational latency and minimizing the ecological footprint associated with massive inference queries.
Adapting to Modern Inference-Native Reasoning Models
The landscape of artificial intelligence interaction has been fundamentally altered by the introduction of specialized inference-native architectures, most notably models such as OpenAI’s o1 and DeepSeek R1. These models represent a structural and behavioral departure from traditional autoregressive text generators.
Internal Logic Pipelines and Reinforcement Learning
Unlike legacy models that require external prompts (such as “Let’s think step by step”) to elicit logical progression, these modern models execute massive, multi-step internal logic implicitly. They have been rigorously trained using specialized Reinforcement Learning with Human Feedback (RLHF), an algorithmic training approach that explicitly rewards the accuracy and thoroughness of intermediate logical steps and internal verification processes, rather than merely evaluating the final generated output.
DeepSeek R1, for instance, operates by isolating its cognitive processing within specific <think> tags, thoroughly analyzing the problem, reviewing its own mathematical logic, and performing self-verification before finalizing the answer in a distinct <answer> block. Because this internal deduction is hardwired into their neural architecture, the prompt engineering strategies used to steer them must be drastically recalibrated.
Recalibrating Instruction Paradigms for Inference
When interfacing with heavy reasoning models, traditional prompting frameworks can actually degrade system performance and induce logical confusion.
- Direct Formulation: These architectures respond optimally to highly direct, clear instructions rather than convoluted step-by-step operational guides. Attempting to force a specific logical pathway onto an o1 or R1 model interferes with its internal reinforcement learning optimization. Operators must state the problem clearly, provide the parameters, and rely on the model’s native mixture-of-experts engine to determine the optimal solution trajectory.
- Avoid Over-Prompting: Providing excessive examples (few-shot prompting) can negatively impact the performance of advanced reasoning models, as it restricts their internal logical flow to the provided pattern rather than allowing the model to explore superior mathematical pathways.
- Targeted Success Criteria: Instructions must clearly and explicitly define the exact parameters for a successful outcome. This encourages the model to iterate its internal logic loops continuously until those precise criteria are mathematically satisfied.
- Output Formatting Specifications: While the logic generation should remain unconstrained, the final format of the output must still be strictly defined to ensure integration. Explicitly demonstrating the desired output format (e.g., demonstrating a JSON structure or tabular layout) ensures the model replicates the structural pattern. Furthermore, operators must be aware of system updates; starting with specific API updates, reasoning models may suppress markdown formatting natively to prioritize pure data. Developers must explicitly include directives like “Formatting re-enabled” within the developer message to override this suppression.
- Domain Specialization Awareness: While these models demonstrate unprecedented superiority in complex analytical tasks—such as independently solving approximately 83% of the highly challenging AIME 2024 math exam on the first attempt, compared to older generalized models scoring roughly 12%—they possess narrower general knowledge domains. They inherently over-analyze trivial tasks, generating excessively complex, verbose explanations for simple factual queries, and may fail at basic trivia without explicit contextual grounding provided in the prompt. Therefore, systematically matching the model class to the task complexity is a critical decision point for any AI engineer.
Empirical Evaluation, Iteration, and Enterprise Operations
The theoretical construction of an instruction payload is merely the first phase of the AI engineering lifecycle. Because LLM development is inherently non-deterministic, creating production-ready systems requires a rigorous, iterative mindset modeled around the scientific method.
The operational workflow for prompt engineering is inherently cyclical, heavily mirroring frameworks like the FutureAGI stack, which emphasizes a continuous loop: generating simulations and datasets, testing agents, evaluating outputs to catch issues, optimizing through reinforcement data, and monitoring via real-time tracing dashboards. A prompt that performs flawlessly during initial, sandboxed testing will almost certainly encounter catastrophic edge cases when exposed to the massive variability of real-world data streams.
Metrics and Programmatic Performance Evaluation
To systematically evolve a mediocre instruction set into a highly robust, production-ready system, engineering organizations must abandon subjective assessments (e.g., “the output sounded better”) in favor of strict mathematical evaluation. This requires building comprehensive evaluation frameworks (evals) that programmatically measure the behavior of prompts across hundreds or thousands of realistic, complex scenarios. Tools designed to refine, grade, and automatically improve prompts are becoming standard infrastructure to level up system reliability.
Key metrics for evaluating prompt engineering include:
- Hallucination Reduction Rates: Utilizing A/B testing methodologies across large sample inputs to calculate the exact percentage drop in fabricated data after introducing new constraints, context retrieval, or verification steps.
- Grounded Accuracy: Measuring how strictly the model adheres to the provided contextual data payload without pulling external, unverified information from its pre-trained weights.
- Algorithmic Success Rates: Utilizing strict metrics like $\text{Pass}@k$ to ensure generated code functions correctly against unit tests.
- Latency and Token Economy: Tracking the exact execution time and computational token consumption before and after applying optimization strategies. Refining prompts should ideally result in faster response times and significantly reduced API expenditures.
- Snapshot Consistency: Because different versions of the exact same model family possess varying probability distributions, production applications must be strictly pinned to specific model snapshots (e.g.,
gpt-4.1-2025-04-14). When an underlying model is upgraded by the provider, the entire evaluation suite must be re-run to ensure the legacy instructions still operate as intended under the new network architecture.
Logging version histories, tracking variable adjustments, and utilizing automated LLM-as-a-judge rubrics allow engineering teams to systematically identify error patterns, track iterative improvements, and scale their AI infrastructure confidently, transforming prompt engineering from an exploratory art into deterministic computer science.